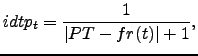Siguiente: Enriquecimiento de términos índice
Subir: Uso del punto de
Anterior: El punto de transición
Elección de términos índice
En numerosas tareas de procesamiento de texto (CT, RI, y AT, entre otras)
es necesario representar los textos usando los términos contenidos en ellos.
Sin embargo, suele hacerse una reducción de estos términos, debido a
la gran cantidad de términos que ocurren en una colección;
además de que el empleo de todos los términos vicia el procedimiento,
sea éste de clasificación, resumen, etc. Así,
se usan variados métodos para elegir los términos que representarán
a los textos; es decir los términos índice.
La selección se hace con base en una puntuación que
el método asigna a cada término: se toma un porcentaje del
total de términos de los textos con la más alta puntuación.
Los métodos de selección pueden ser supervisados o no supervisados;
esto es, los supervisados utilizan información acerca de los términos
que tienen mayor capacidad para determinar una clase, según
la colección de entrenamiento [Sebastiani2002].
Dos de los métodos supervisados más efectivos son:
CHI, que mide la independencia entre
la clase de un texto y un término contenido en el texto; e IG cuya
puntuación representa la carencia de información que provee un
término para predecir la clase del texto en el que ocurre. En este
trabajo utilizaremos métodos no supervisados
puesto que resulta más útil para el tipo de problema que se
pretende resolver.
Consideremos una colección de textos
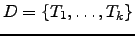 .
Tres son los métodos que abordaremos:
.
Tres son los métodos que abordaremos:
- Frecuencia entre documentos (DF).
- Asigna a cada término
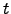 el valor
el valor
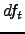 , que es el número de textos de
, que es el número de textos de 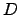 en los que ocurre .
Se supone que los términos raros (baja frecuencia) difícilmente
ocurrirán en otro texto y, por tanto, no tienen capacidad para
predecir la clase de un texto.
en los que ocurre .
Se supone que los términos raros (baja frecuencia) difícilmente
ocurrirán en otro texto y, por tanto, no tienen capacidad para
predecir la clase de un texto.
- Fuerza de enlace (TS).
- La puntuación que se da a un término
está definida por:
donde
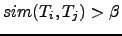 , y
, y 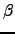 es un umbral que debe ajustarse
observando la matriz de similitudes entre los textos.
Con base en su definción, puede decirse que un va-lor alto
de
es un umbral que debe ajustarse
observando la matriz de similitudes entre los textos.
Con base en su definción, puede decirse que un va-lor alto
de 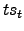 significa que contribuyó a que, al menos, dos documentos
fueran más similares que el umbral .
significa que contribuyó a que, al menos, dos documentos
fueran más similares que el umbral .
- Punto de transición (PT).
- Los términos reciben un valor
alto entre más cerca esté su frecuencia del PT.
Una forma de hacerlo es calcular el inverso de la distancia entre
la frecuencia del término y el PT:
donde
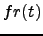 es la frecuencia local, (en el texto, y no en la colección);
esto es, los términos reciben una puntuación en cada texto.
es la frecuencia local, (en el texto, y no en la colección);
esto es, los términos reciben una puntuación en cada texto.
DF es un método muy simple pero efectivo, por ejemplo, en categorización
de textos (CT) compite con
los clásicos supervisados CHI e IG.
También el método PT tiene un cálculo simple, y puede usarse
de diversas formas. En especial para CT se ha visto mejor desempeño con
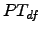 , o PT global; esto es, se considera , en lugar de la frecuencia
local de los términos en cada texto de la colección.
, o PT global; esto es, se considera , en lugar de la frecuencia
local de los términos en cada texto de la colección.
Los métodos DF y PT están en la clase de complejidad
lineal con respecto al número de términos de la colección.
El método TS (Term Strength) es muy dispendioso en su cálculo,
pues requiere calcular la matriz de similitudes entre documentos; cuadrático
en el número de textos. Pero se reportan resultados de AT cercanos a los
métodos supervisados [Liu
2003].
Subsecciones
Siguiente: Enriquecimiento de términos índice
Subir: Uso del punto de
Anterior: El punto de transición
David Pinto
2006-05-25