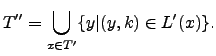Empleamos una técnica basada en la pro-puesta de Hindle [Hindle1990] que apoya los métodos de construcción de thesauri. Se dice que dos términos son vecinos cercanos cuando uno de ellos coocurre con el otro entre los de mayor frecuencia, y viceversa. En estos métodos es común utilizar una medida de asociación como la información mutua. Sin embargo, estas medidas se usan en textos grandes, y por ello nos limitamos a utilizar solamente la frecuencia de los términos.
A cada uno de los términos del vocabulario de una colección de textos se asocia una lista de términos que coocurren frecuentemente en las oraciones de la colección. Si consideramos que los términos índice representan a cada texto, entonces los términos asociados a los índice representarán de una manera más rica a los textos.
La lista de asociación para cada término índice se calcula
como sigue. Para cada término, ![]() , en el vocabulario de la colección
su lista es:
, en el vocabulario de la colección
su lista es:
Denotemos con ![]() los términos índice de
los términos índice de ![]() .
Consideramos para cada término índice
.
Consideramos para cada término índice ![]() (
(![]() ) su
lista de asociaciones,
) su
lista de asociaciones, ![]() , ordenada por la segunda componente de sus
miembros:
, ordenada por la segunda componente de sus
miembros:
![]() ,
,
![]() (
(
![]() ). En ésta se realiza un recorte de las parejas con
). En ésta se realiza un recorte de las parejas con
![]() , debido a que son términos que no contribuyen al agrupamiento
así como los términos con frecuencias muy altas2.
, debido a que son términos que no contribuyen al agrupamiento
así como los términos con frecuencias muy altas2.
Sea ![]() la lista de palabras asociadas al término
la lista de palabras asociadas al término
![]() después de la eliminación de términos con frecuencias
extremales. La expansión del conjunto de términos índice
después de la eliminación de términos con frecuencias
extremales. La expansión del conjunto de términos índice ![]() es:
es: