


Siguiente: Elección de términos índice
Subir: Uso del punto de
Anterior: Trabajos relacionados
El punto de transición (PT) es una consecuencia
de las observaciones de George Kinsley Zipf,
quién formuló la ley de frecuencias de palabras de un texto
(Ley de Zipf), la cual establece que el producto del rango por la
frecuencia de una palabra es constante [Zipf1949].
Esta regularidad estadística proviene de la tensión entre dos fuerzas
inherentes a los lenguajes naturales: unificación y
diversificación. La primera conduce a emplear términos
de índole general, mientras que la segunda al uso de términos
específicos. Los términos ligados a la primera fuerza
establecen nexos con el entorno del texto, y los de la segunda detallan
su contenido. Esto sugiere que las palabras que caracterizan un texto
no sean ni las más frecuentes ni las menos frecuentes, sino las que se
encuentran en una frecuencia media de ocurrencia dentro del texto
[Luhn1958].
Algunos autores,
llevaron a cabo experimentos con las ideas anteriores; la
indización automática de textos, y la identificación de palabras
clave de un texto [Urbizagástegui1999]. A partir de la ley de ocurrencia
de palabras con baja frecuencia propuesta por Booth [Booth1967], fue posible
derivar una fórmula para localizar la frecuencia que divide en dos
al vocabulario de un texto: las palabras de baja, y alta frecuencia;
justamente, el llamado punto de transición. La fórmula para
calcular el PT es:
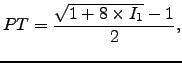 |
(1) |
donde 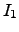 representa el número de palabras con frecuencia 1.
De acuerdo con la caracterización de las frecuencias medias [Booth1967],
el PT puede localizarse, en el vocabulario de un texto, identificando
la frecuencia más baja, de las altas, que no se repita. Este método es
particularmente útil para textos cortos; en la obtención del
extracto de un texto [Bueno, Pinto, y Jiménez-Salazar2005], y la identificación de las
palabras clave de un texto [Pinto y Pérez2004].
representa el número de palabras con frecuencia 1.
De acuerdo con la caracterización de las frecuencias medias [Booth1967],
el PT puede localizarse, en el vocabulario de un texto, identificando
la frecuencia más baja, de las altas, que no se repita. Este método es
particularmente útil para textos cortos; en la obtención del
extracto de un texto [Bueno, Pinto, y Jiménez-Salazar2005], y la identificación de las
palabras clave de un texto [Pinto y Pérez2004].
Ha habido algunas aplicaciones que revelan la utilidad del PT.
Específicamente, en el corte de la selección de
términos por los métodos clásicos de selección [Moyotl y Jiménez2004],
y la selección de términos para ca-tegorización de textos
[Moyotl-Hernández y
Jiménez-Salazar2005].
Debido a que un resumen reúne las características de cualquier texto,
el problema de frecuencia baja de los términos, decisivo en la
representación para procesamiento, puede atenuarse considerando que se cumplen
las leyes derivadas de la de Zipf. En esencia, esta hipótesis
es la que se pretende reforzar en el presente trabajo.
Siguiente: Elección de términos índice
Subir: Uso del punto de
Anterior: Trabajos relacionados
David Pinto
2006-05-25