
![]()
Profesor: M.C. David Eduardo Pinto Avendaño
Indice
Definiciones Preliminares
Sistema
Sistema abierto
X/OPEN
Bell Labs
NCR
Sistema cerrado
Protocolo
Especificación de un protocolo
Implementación de un protocolo
Estandarización
Estandar
Normas de Jure
Normas de Facto
Organizaciones
OSF
X/OPEN
OPEN GROUP
MISION
Sistemas Abiertos
NOS
DOS
Sistemas Distribuidos
Introducción
Sistemas distribuidos contra centralizados
Sistemas distribuidos contra computadoras aisladas
Desventajas de los sistemas distribuidos
Taxonomía de las computadoras
Clasificación de Flynn
Clasificación de Kuck
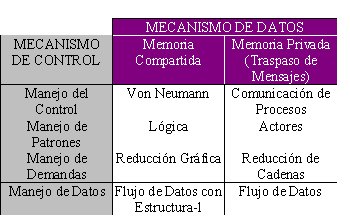
Clasificación de Treleaven
Clasificación de Gajski y Pier
Taxonomía de los sistemas de computo paralelos y distribuidos
Multiprocesadores
Con Base en bus
Con Conmutador
Multicomputadoras
Con Base en bus
Con Conmutador
Conceptos de Software
Definiciones Preliminares
Sistema
Un conjunto de elementos que interactuan entre si para llevar acabo
alguna tarea que en un momento compartan algún tipo de recurso.
Sistema Abierto
Es aquel sistema que permite la intercomunicación de sistemas heterogeneos.
Características de sistemas abiertos:
- Interoperabilidad: Construir un sistema independientemente de la plataforma.
- Portabilidad: Un software que pasa de una arquitectura a otras sin problemas.
- Manejabilidad: Basar un sistema de estándares.
- Reusabilidad: Usar elementos del mismo sistema para expanderse y permitir la modificación.
X/OPEN
Cualquier ambiente de computación independiente del vendedor que consiste
en productos y tecnologías interoperables que son muy comunes y que han
sido diseñadas e implementadas de acuerdo con los estándares.
Bell Labs
Sistemas Operativos portables que corren en una variedad de plataformas.
NCR (National Cash Register)
Conjunto de estándares que habilitan a diferentes computadoras y subsistemas a
operar conjuntamente.
Sistema Cerrado
El hardware y el software ofrecido por un fabricante solo esta disponible para
las computadoras de dicho fabricante..
Protocolo
Reglas para la comunicación, especificación e implementación de estándares.
Especificación de un protocolo
Reglas formales realizadas de manera teórica para la posterior implementación
de n protocolos, bajo las cuales podrán regirse o basarse.
Implementación de un protocolo
Es aplicar los métodos de especificación para realizar propiamente el
protocolo.
Lo mas importante de la implementación de un protocolo es que si estan basados
en una especificación anterior entonces las implementaciones deberán ser
compatibles.
Estandarización
Estándar
Es un protocolo que tiene características superiores, que este siendo
introducida por organizaciones influyentes, o sea, utilizado por la mayoría de
las personas con un efecto de continuidad en cascada.
Normas de Jure
Son las normas que dan pie para que un protocolo se vuelva estándar.
Son aquellas normas que son dadas por alguna organización y que deben ser
tomadas por todas las demás personas tal cual fuera una ley.
Normas de Facto
Son aquellas normas que son tomadas por las personas debido a que a través del
tiempo estas se han dado cuenta que muchas normas son funcionales( o por lo
menos así lo creen).
Organizaciones que se dedican a la estandarización
- OSF ( Open Software Fundation):Creada en 1988 por los mayores vendedores de computadoras.
- X/OPEN:Organización independiente y mundial de sistemas abiertos apoyada por la mayoría de los desarrolladores más grandes de sistemas de información, organizaciones de usuarios y compañías de software.
- OPEN GROUP: En febrero de 1996 se llevo acabo la consolidación de los dos consorcios líderes en sistemas abiertos: X/OPEN Company Open Software Foundation (OSF).
Mision: Permitir al consumidor elegir en la implementación de sistemas
de información a multivendedores.
Sistemas abiertos
NOS
Sistema Operativo de Red.
DOS
Permite la compartición de recursos entre diversos grupos heterogéneos
generalmente, y la existencia de multiples equipos, es transparente hacia el
usuario.
Sistemas Distribuidos
Introducción
Desde 1995, cuando coménzo la era de la computadora moderna hasta cerca
de 1985, las computadoras eran grandes y caras.
La mayor parte de las organizaciones tenia tan solo un puñado de computadoras y
por carecer de una forma para conectarlas, estas operaban por lo general en
forma independiente entre si.
A partir de la mitad de la década de 1980, dos avances tecnológicos comenzaron
a cambiar la situación. El primero fue el desarrollo de poderosos microprocesadores.
En principio, se disponia de máquinas de 8 bits, pronto se volvieron comunes
los CPU de 16,32 e incluso de 64 bits; tenían el poder de computo de una
computadora mainframe de tamaño respetable, pero por una fracción de su precio.
El segundo desarrollo fue la invención de las Redes de Area Local (LAN).
Las redes de área local permiten conectar docenas e incluso cientos de máquinas
dentro de un edificio, de tal forma que se pueden tranferir pequeñas
cantidades de información entre ellas en un milisegundo o tiempo parecido.
Las Redes de Area Amplia (WAN) permiten que millones de máquinas en toda la
Tierra se conecten con velocidades que varian de 64 Kbps. a Gbps. Para ciertas
redes experimentales avanzadas.
El resultado neto de estas tecnologías es que hoy en día, no solo es posible,
sino fácil, reunir sistemas de computo compuestos por un gran número de CPU,
conectados mediante una red de alta velocidad. Estos reciben el nombre genérico
de sistemas distribuidos, en contraste con los sistemas centralizados anteriores(
o sistemas de un solo procesador), que constan de un CPU, su memoria, sus
periféricos y algunas terminales.
Solo existe una mosca en la sopa: el software; los sistemas distribuidos
necesitan un software radicalmente distinto al de los sistemas centralizados.
Los sistemas operativos necesarios para estos sistemas distribuidos están
apenas en una etapa de surgimiento.
Sistema Distribuido
Colección de computadoras independientes que aparecen ante los usuarios del
sistema como una única computadora.
Ejemplos: Una red de estaciones de trabajo en una universidad o compañía,
una fabrica de robots, un banco con cientos de sucursales, etc.
Ventajas de los sistemas distribuidos con
respecto a los centralizados
Hace un cuarto de siglo, una persona experta en computadoras Herb Grosch,
anuncio la Ley de Grosch: "El poder de computo de CPU es
proporcional al cuadrado de su precio". Si se paga el doble, se obtiene
cuatro veces el desempeño.
Esta observación encajo bien en la tecnología mainframe de su tiempo y
provocó que muchas organizaciones compraran una sola máquina, la mas
grande que pudieran conseguir.
Con la tecnología del microprocesador, la ley de Grosh ya no es valida. Por
unos cuantos cientos de dólares, es posible comprar un microcircuito de CPU
que puede ejecutar mas instrucciones por segundo que las que realizaba
uno de los más grandes mainframes de 1980. Si uno esta dispuesto a pagar el
doble, se obtiene el mismo CPU, solo que con una velocidad un poco mayor.
Las ventajas de los sistemas distribuidos sobre los centralizados son:
- Economía: Los microprocesadores ofrecen mejorar la proporción precio/rendimiento de las mainframes.
- Velodidad: Un sistema distribuido puede tener mayor poder de computo que un mainframe.
- Distribución inherente: Algunas aplicaciones utilizan máquinas que están separas a cierta distancia.
- Confiabilidad: Si una máquina se descompone, el sistema puede sobrevivir como un todo.
- Crecimiento por incrementos: Se puede añadir poder de computo en pequeños incrementos.
Ventajas de los sistemas distribuidos
con respecto a las computadoras aisladas
- Datos compartidos: Permiten que varios usuarios tengan acceso a una base de datos común.
- Dispositivos compartidos: Permiten que varios usuarios compartan periféricos caros, como las impresoras.
- Comunicación: Facilita la comunicación de persona a persona, por ejemplo mediante el correo electrónico.
- Flexibilidad: Difunde la carga del trabajo entre las máquinas disponibles en la forma mas eficaz en cuanto a los costos.
Desventajas de los sistemas distribuidos
- Software: Existe poco software para los sistemas distribuidos de la actualidad.
- Redes: La red se puede saturar o causar otros problemas.
- Seguridad: Un acceso sencillo también se aplica a datos secretos.
Taxonomía de las computadoras
Con el paso de los años, se han propuesto diversos esquemas de clasificación
para los sistemas de computo con varios CPU, pero ninguno de ellos ha tenido un
éxito completo ni se ha adaptado de manera amplia.
La taxonomía más citada es la de Flynn (1972). Flynn eligió dos características
consideradas por el como esenciales: el número de flujos de instrucciones y el
número de flujo de datos.
Clasificaciones de las computadoras:
- Clasificación de Flynn
 .
.
- Clasificación de Kuck

- Clasificación de Treleaven.
- Clasificación de Gajski y Pier.
Una computadora con un flujo de instrucciones y una de datos se llama SISD
(Single Instruction Single Data). Todas las computadoras tradicionales de un
procesador caen dentro de esta categoría desde las computadoras personales
hasta los mas grandes mainframes.
La siguiente categoría es SIMD (Single Instruction Multiple Data), con un flujo de instrucciones y varios flujos de datos. Este tipo se refire a ordenar procesadores con unidad de instrucción y después instruye a varias unidades de datos para que la lleven a cabo en paralelo, cada uno con sus propios datos. Estas máquinas son útiles para los computos los que respeten los mismos cálculos en varios conjuntos de datos.
MISD(Multiple Instruction Single Data): Con un flujo de varias instrucciones y un flujo de datos. Ninguna de las computadoras conocidas se ajusta a este modelo.
MIMD(Multiple Instruction Multiple Data): Significa un grupo de computadoras independientes, cada una con su propio contador del programa y datos, todo sistema distribuido se encuentra dentro de esta categoría.
Todas las computadoras MIMD se dividen en dos grupos: Aquellas que tienen
memoria compartida llamadas multiprocesadores y aquellas que no, que a veces
reciben el nombre de multicomputadoras. La diferencia esencial es esta: un
multiprocesador existe en un espacio de direcciones virtuales, compartidos por
todos los CPU. En contraste, en una música de computadoras, cada máquina tiene
su propia memoria pronto un ejemplo común de computdoras es una colección de
computadoras personales conectadas mediante una red.
Cada una de esas categorías se puede dividir, con base a la arquitectura de la
red de interconexión. Estas dos categorías son bus y conmutador. En las
primeras indica que existe una red, plano de base, Bus, cable u otro medio que
conecte a todas las máquinas.
Los sistemas con conmutador no tiene sólo una columna vertebral, sino que tiene
cables individuales de una máquina a otra utilizando varios patrones diferentes
de cableado. Los mensajes se mueven a través de los cables y se toma una
decisión explícita de conmutación en cada etapa, para dirigir el mensaje a lo
largo de uno de los cables de salida.
otra dimensión de la toxonomía es que, en ciertos sistemas, las máquinas estan fuertemente
acoplado y en otras estan debidamente acoplado. En un sistema fuertemente
acoplado, el retraso que se experimenta al enviar un mensaje de una computadora
a otra es corto y la tasa de transmisión de datos (el número de bits por
segundo) que se pueden transferir es alta.
En un sistema débilmente acoplado ocurre lo cotrario: el retraso de los
mensajes entre las máquinas es grande y la tasa de transmisión de los datos es
baja.
Los sistemas fuertemente acoplados tienden a utilizarse mas como sistemas
paralelos y los débilmente acoplados tienden a utilizarse como sistemas
distribuuidos.
Taxonomía de los sistemas de computo paralelos y distribuidos
Multiprocesadores
- Multiprocesador con base en bus
Constan de cierta cantidad de CPU, conectados a un bus
común, junto con un modelo de memoria.Una configuración sencilla consta de un
plano de base de alta velocidad o tarjeta madre, en el cual se pueden
insertar las tarjetas de memoria y el CPU. Un bus típico tiene 32 o 64 líneas
de direcciones 32 o 64 líneas de datos y 32 o más líneas de control, todo lo
cual opera en paralelo.
El problema con este esquema es que si solo se dispone de 4 o 5 CPU, el bus
estará por lo general sobrecargado y el rendimiento disminuirá en forma
drástica. La solución es añadir una memoria cache de velocidad entre el
CPU y el bus. El cache guarda palabras de acceso reciente.Todas las
solicitudes de la memoria pasan a través del cache. Si la palabra solicitada se
encuentra en él cache, este responde al CPU y no se hace solicitud alguna al
bus. Si el cache es lo bastante grande, la probabilidad de éxito ( tasa de
encuentros) será alta y la cantidad de tráfico en el bus por cada CPU
disminuirá en forma drástica, lo que permite un número mayor de CPU en el
sistema.
- Multiprocesador con conmutador
Para construir un multiprocesador con mas de 64
procesadores, es necesario un método distinto para conectar cada CPU con la
memoria. Una posibilidad es dividir la memoria en módulos y conectarlos a los
CPU con un Comnutador de Cruceta
Cada CPU y cada memoria tiene una conexión que sale de el. En cada
intersección esta un delgado conmutador de punto de cruce electrónico que
el hardware puede abrir o cerrar. Cuando su CPU desea tener acceso a una
memoria particular, el conmutador del punto de cruce que los conecta se cierra
de manera momentánea para permitir dicho acceso. La virtud del conmutador de
cruceta es que muchos CPU intentan tener acceso a la misma memoria en forma
simultánea, uno de ellos deberá de esperar.
La desventaja del conmutador de cruceta es que con n CPU y n memorias, se
necesitaran n conmutadores en los puntos de cruce. Si n es grande, este número
puede ser prohibido.
En resumen los multiprocesadores basados en buses, incluso con caches monitores
quedan limitados a lo más a 64 CPUs por la capacidad del bus. Para
rebasar estos limites, es necesario una red con conmutador, como una de
cruceta, una red omega o algo similar. Los grandes conmutadores de cruceta y
las grandes redes son muy caros y lentos.
Las máquinas NUJA necesitan complejos algoritmos para la buena colocación
del software la conclusión es clara: la construcción de un
multiprocesador grande fuertemente acoplado y con memoria compartida es difícil
y cara.
Multicomputadoras
- Multicomputadoras con base en bus
La construcción de una multicomputadora(sin memoria
compartida) es fácil. Cada CPU tiene conexión directa con su propia memoria
global, el único problema restante es la forma en que las CPU se comunicaran
entre si. Aquí también se necesita cierto esquema de interconexión, pero como
solo es para la comunicación entre un CPU y otro, el volumen de tráfico será de
varios ordenes menor en relación con el uso de una red de interconexión para el
tráfico CPU-memoria.
Una multicomputadora con base en bus es similar desde el punto de vista
topológico al multiprocesador basado en bus con plano de base de alta
velocidad; puede ser una LAN de menor velocidad; es mas a menudo una colección
de estaciones de trabajo en una LAN que una colección de tarjetas de CPU que se
insertan en un bus rápido.
- Multicomputadoras con conmutador
Se han propuesto y construido
varias redes de interconexión, pero todas tienen la propiedad de que cada CPU
tiene acceso directo y exclusivo a su propia memoria particular. Existe dos
tipologías populares, una retícula y un hipercubo. Las retículas son fáciles de
comprender y se basan en las tarjetas de circuitos impresos. Se adecuan mejor a
problemas con naturaleza bidimencional inherente, como la teoría de graficas o
la visión.
Un hipercubo es un cubo n-bidimencional. El hipercubo de dimensión 4 se puede
pensar como dos cubos ordinarios, cada uno de los cuales cuenta con 8
vértices y 12 aristas. Cada vértice es un CPU, cada arista es una conexión
entre dos CPU. Se conectan los vértices correspondientes de cada uno de los
cubos.
Conceptos de Software
Los sistemas operativos no se pueden clasificar tan fácil como el hardware
por su propia naturaleza, el software es vago y amorfo. aun así es mas o menos
posible distinguir dos tipos de sistemas operativos para los sistemas de varios
CPU: los débilmente acoplados y los fuertemente acoplados. El software débil o
fuertemente acoplado es un tanto análogo al hardware débil o fuertemente
acoplado.
El software débilmente acoplado principalmente permite que las máquinas y los
usuarios de un sistema distribuido sean independientes entre si en lo
fundamental, pero que interactuan en cierto grado.
Sistemas Operativos de Redes
Los sistemas operativos de red están formados por un software débilmente
acoplado en un hardware débilmente acoplado. De no ser por el sistema
compartido de archivos, a los usuarios les parecería que el sistema
consta de varias computadoras. Cada una puede ejecutar su propio sistema
operativo y hacer, lo que el propietario quiera. En esencia no hay coordinación
alguna, exepto por la regla de que el tráfico cliente-servidor debe obedecer
los protocolos del sistema.
Sistemas Realmente Distribuidos
El siguiente paso en la evolución es la del software fuertemente acoplado en hardware
débilmente acoplado( en multicomputadoras). El objetivo de un sistema de este
tipo es crear la ilusión en las mentes de los usuarios que toda la red de
computadoras es un sistema de tiempo compartido, en vez de una colección de
máquinas diversas. La idea esencial es que los usuarios no deben ser
conscientes de la existencia de varios CPU en el sistema. Ningún sistema en la
actualidad cumple este requisito, pero hay varios candidatos promisionarios a
este horizonte.
Características de un sistema distribuido
Debe existir un mecanismo de comunicación global entre los
procesos de forma que cualquier proceso pueda comunicarse con cualquier otro.
No tiene que haber distintos mecanismos en distintas máquinas o distintos
mecanismos para la comunicación. La mezcla de acceso a las listas de control,
los bits de protección de UNIX y las diversas capacidades no producirán una
imagen de único sistema.
La administración de procesos también debe ser la misma en todas partes, la
forma en que se crean. destruyen, inician y detienen los procesos no debe
variar de una máquina a otra. En resumen, la idea detrás de los sistemas
operativos de red en el sentido de que cualquier máquina puede hacer lo que
desee mientras obedezca los protocolos estándar cuando participe en una
comunicación cliente-servidor, no es suficiente.
Sistemas de multiprocesador con
tiempo compartido
El software y el hardware fuertemente acoplados forman este tipo de sistemas.
Aunque existen varias máquinas de propósito general en esta categoría, los
ejemplos más comunes son los multiprocesadores que operan como un sistema de
tiempo compartido de UNIX, solo que con varios CPU, en vez de uno. Para
el mundo exterior, un multiprocesador con 32 CPU de 30 MIPS (esta es la imagen
de único sistema analizada anteriormente), excepto por el hecho de que todo el
diseño se puede centralizar.
Las características clave de este tipo de sistema es la existencia de una cola
de ejecución: una lista de todos los procesos en el sistema que no están
bloqueados en forma lógica y listos para su ejecución es una estructura de
datos contenida en la memoria compartida.
Diferencias entre los tipos de sistemas operativos analizados
|
ELEMENTO |
RED |
DISTRIBUIDO |
MULTIPROCESADOR |
|
Se ve como procesador virtual |
NO |
SI |
SI |
|
Todos ejecutan el mismo S.O. |
NO |
SI |
SI |
|
Número de copias del S.O. existentes |
N |
N |
1 |
|
Como se logra la comunicación |
Archivos compartidos |
Mensajes |
Memoria compartida |
|
Se requiere acuerdo en los protocolos de la red |
SI |
SI |
NO |
|
Existe cola de ejecución |
NO |
NO |
SI |
|
Existe semántica definida para archivos compartidos |
Por lo general NO |
SI |
SI |
Aspectos de Diseño
Algunos de los aspectoss claves del diseño con los que deben trabajar las personas que piensan construir un S.O. distribuido son:
Transparencia
Capacidad de un sistema de engañar a los usuarios de forma que piensan que la
colección de máquinas es tan solo un sistema de tiempo compartido de un
procesador.
Transparencia de localización: Los usuarios no pueden indicar la locaclización
de los recursos.
Transparencia de migración: Los recursos se pueden mover a voluntad sin cambiar
sus nombres.
Transsparencia de replica: Los usuarios pueden compartir recursos de manera
automática.
Transparencia de concurrencia: Varios usuarios pueden compartir recursos de
manera automática.
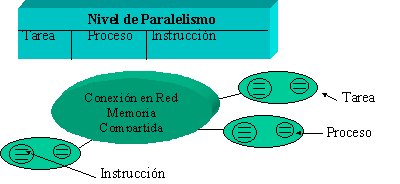
Transparencia de paralelismo: Las actividades pueden ocurrir en paralelo sin el
conocimiento de los usuarios.
Flexibilidad
Es importante que el sistema sea flexible, ya que apenas se esta aprendiendo a
construir sistemas distribuidos.Es probable que este proceso tenga muchas
salidas falsas y una considerable retroalimentación.
Confiabilidad
Uno de los objetivos originales de la construcción de sistemas
distribuidos fue el hacerlos mas confiables que los sistemas con un procesador.
Las ideas es que si una máquina falla alguna otra se encargue del trabajo.
La confiabilidad abarca los siguientes aspectos:
Disponibilidad: fracción de tiempo en que se pueden usar el sistema.
Seguridad: Los archivos y otros recursos deben ser protegidos contra el
uso no autorizado.
Tolerancia a fallos: Debe soportar las posibles fallas existentes sin
denotarlas al usuario y seguir trabajando como un todo.
Desempeño
La forma en que el sistema realiza el trabajo eficientemente midiéndose a veces
en cuanto al tiempo de respuesta, el rendimiento(número de trabajos por hora),
el uso del sistema y cantidad consumida de la capacidad de la red.
Escalabilidad
Se refiere a que un sistema distribuido debe ser apto para crecer en cuanto al
rendimiento de recursos, etc. De acuerdo a la necesidad de los usuarios.
Comunicación de los Sistemas Distribuidos
La diferencia más importante entre un sistema distribuido y
un sistema con un procesador es la comunicación entre procesos. En un sistema
con un procesador, la mayor parte de la comunicación entre procesos supone de
manera implicita la existencia de la memoria compartida.
En un sistema distribuido, no existe tal memoria compartida por lo que toda la
naturaleza de la comunicación entre procesos debe planearse a partir de cero.
Clientes y Servidores
El modelo cliente-servidor se presenta con la idea de
estructurar el sistema operativo como un grupo de procesos en cooperación
llamados servidores, que ofrezcan servicios a los usuarios llamados clientes.
Una máquina puede ejecutar un proceso o varios clientes, varios servidores o
combinaciones de ambos, lo usual es que el modelo cliente-servidor se base en
un protocolo solicitud/respuesta sencillo y sin conexión. El cliente
envía un mensaje de solicitud al servidor para pedir cierto servicio.
El servidor hace el trabajo y regresa los datos solicitados o un código de
error para indicar la razón por la cual un trabajo no se puede llevar a cabo.
La principal ventaja es su sencillez, el cliente envía un mensaje y
obtiene una respuesta. No se tiene que establecer una conexión sino hasta que
este se utilice.
El mensaje de respuesta sirve como reconocimiento de la solicitud.
Otra ventaja es la eficiencia: la pila del protocolo es mas corta y por tanto
mas eficiente. Si todas la máquinas fuesen idénticas, solo se necesitarian tres
niveles de protocolos. La capa física y de enlace de datos se encargaran de
llevar los paquetes del cliente al servidor y viceversa. Esto siempre lo maneja
el hardware. No se necesita un ruteo y tampoco se establecen conexiones por lo
que no se utilizan las capas 3 y 4. La capa 5 es el protocolo
solicitud/respuesta; define el conjunto de solicitud validas y el conjunto de
respuestas validas a estas solicitudes.Tampoco se utilizan las capas superiores
debido a esta estructura tan sencilla se pueden reducir los servicios que presta
el micronucleo.
Direccionamiento
Para que un cliente pueda enviar un mensaje a un servidor
debe conocer la dirección de este.
Este método consiste en asignarle a cada proceso una dirección que no contenga
un número de máquina. La forma de lograr esto es mediante un asignador
centralizado de direcciones los procesos que mantengan tan solo un contador. Al
recibir solicitud de dirección el asignador regresa el valor actual del
contador y los incrementa en uno. La desventaja de este esquema es que los componentes
centralizados no se pueden extender a los grandes sistemas por lo cual hay que
evitarlo.
¿Como sabe el núcleo emisor a cual máquina enviar el mensaje?
En una LAN que soporte transmisiones el emisor puede transmitir un paquete
especial de localización con la dirección de 1 proceso destino puesto que es un
paquete de transmisión, será recibido por todas las máquinas de la red. Todo
los nucleos verifican si la dirección es suya y, en caso de que lo sea
regresa un mensaje de aquí esta con su dirección en la red.
Los métodos más comunes de direccionamiento de los procesos son:
Integrar machine number al código del cliente.
Dejar que los procesos elijan direcciones al azar; se localizan mediante
transmisión.
Colocar los nombres con ASCII de los servidores en los clientes, buscarlos al
tiempo de ejecución.
Cada uno de estos métodos tienen sus problemas. El primero no es transparente,
el segundo genera carga adicional en el sistema y el tercero necesita un
componente centralizado.
Comunicación
Cuando un proceso envía un mensaje a otro proceso , el proceso que envío el mensaje se bloquea hasta que el segundo le envía un mensaje de recibido.
Primitivas con bloqueo
Cuando un proceso llama a Send especifica un destino y un
buffer donde envía ese destino, mientras se envía el mensaje, el proceso emisor
se bloquea es decir se suspende. La instrucción que sigue a la llamada a
send no se ejecuta sino hasta que el mensaje se envía en su totalidad.
Una llamada a receive no regresa el control sino hasta que en realidad se
reciba un mensaje y este se coloque en el buffer de mensajes a donde apunta el
parámetro.
Primitivas sin bloqueo
Si send no tiene bloqueo, regresa de inmediato el control a
quien hizo la llamada, antes de enviar el mensaje.
Ventajas: El proceso emisor puede continuar su computo en forma paralela con la
transmisión de mensajes en vez de tener inactivo al CPU.
Desventaja: El emisor no puede modificar el buffer de mensajes sino hasta que
el mensaje haya sido enviado.
Las consecuencias de que el proceso escriba sobre el mensaje durante la
transmisión son demasiado graves.
El emisor no tiene idea de cuando termine la transmisión.
Un proceso le envía un mensaje a otro proceso mediante un buffer el cual se
encarga de enviar el mensaje mientras que el CPU del emisor ejecuta otras
opciones.
Primitivas no almacenadas
Un proceso envía un mensaje de forma o manera directa a otro
proceso.
Desventaja: Tarda más tiempo en liberarse el proceso que envía el mensaje.
Ventaja: El envío de mensajes es mas rápido.
Primitivas almacenas en buffer
Un proceso envía un mensaje a otro proceso depositándolo en el buffer, tomando el proceso al que se le envía cuando lo necesita.
Primitivas confiables y no confiables
Primer método: Se envía el mensaje y no hay respuesta de
recibido. Similar a un correo, se envía la carta y no se sabe si llego o no.
Segundo método: El proceso 1 le envía el mensaje al proceso 2, el proceso 2 le
envía un mensaje de reconocimiento( de que el mensaje ya le llego) de modo
transparente, después de decirle que ya lo recibió se lo manda y el proceso uno
envía un mensaje de que ya le llego al proceso dos de manera transparente.
Tercer método: El proceso uno le envía un mensaje del proceso 2 este le envía
un mensaje de respuesta y el proceso 1 le envía otro mensaje de reconocimiento
(de que si le llego) al proceso de 2 de manera transparente.
Cuarto método: Este consiste en enviar un mensaje y esperar la respuesta en un
tiempo determinado mediante un cronometro.
RPC Llamada a un procedimiento remoto
Operaciones Básicas
Una máquina va a ejecutar un proceso que está en otra
máquina.
RPC se utiliza para representar mejor abstracción en la comunicación entre
procesos que se manejan como E/S
Con RPC un proceso cliente que se ejecuta en una máquina, llama a un
procedimiento que se ejecuta en otra. El sistema de tiempo de ejecución inmerso
en los procedimientos de resguaro, maneja la recolección de parámetros, la
construcción de mensajes y de la interfaz con el núcleo para el desplazamiento
de los bits.
Problemas de RPC:
Hay que localizar el servidor correcto.
Es dificil la transferencia de los apuntadores y estructuras de datos
complejos.
Es dificil utilizar variables globales.
La implementación eficiente de RPC no es directa y requiere de una reflexión
cuidadosa.
Montar un sistema que rutee bien la dirección de la máquina a conectar.
Elaborar estructuras de datos no tan complejas, mas simples.
Utilizar variables locales que suplan la f(x) de las variables globales.
Ser estrictas en el paso de parámetros y en la información a enviar y a
recibir.
Comunicación en Grupo
Conjunto de procesos que actúan juntos en ciertos sistemas en alguna forma determinada por el usuario.
Propiedades del Grupo
Cuando un mensaje se envía al propio grupo, todos los miembros de este lo
reciben.
Son dinámicos: creación, destrucción y membresia (se pueden crear nuevos y
destruir los anteriores).
Un protocolo puede enviar un mensaje a un grupo de servidores sin tener que
conocer el número o localización exacta de tales servidores.
La implementación del grupo depende en gran medida del hardware sobre el cual
se piensa implementar.
Comunicación Puntual
Un emisor y varios receptores.
Comunicación 1 a muchos
Un emisor y varios receptores.
Grupos Cerrados
Solo los miembros del grupo pueden enviar mensajes hacia el grupo. los extraños
no pueden enviar mensajes al grupo como un todo pueden enviar a miembros del
grupo en lo individual se utilizan principalmente en el proceso paralelo.
Grupo Abierto
Cualquier proceso del sistema puede enviar mensajes a cualquier grupo.
Grupos de compañeros
Aquí todos los procesos son iguales.
Nadie es el jefe y todos las decisiones se manejan de manera colectiva.
Ventajas: El grupo de compañeros es simétrico y no tienen puntos de
falla, el grupo solo se vuelve mas pequeño pero puede continuar.
Desventajas: La toma de decisiones es mas dificil, para tomar una decisión hay
que pedir un voto, lo que produce cierto retraso y costo.
Programación mas compleja.
Comunicación mas complicada.
Grupo jerarquico
Un proceso es el coordinador y todos los demás son trabajadores.
En este modelo si se genera una solicitud de un trabajo, este se envía al
coordinador este decide cual de los trabajadores es el más adecuado para
llevarla a cabo y se envía.
Ventaja: Mientras se mantenga en ejecución puede tomar decisiones sin molestar
a los demás.
Desventaja: Un punto de falla, si el servidor de grupos falla, deja de existir
el manejo de los mismos, es muy probables que todos los grupos deban
reconstruirse a partir de cero, terminando con el trabajo realizado hasta
entonces.
Forma distribuida
En un grupo abierto un extraño puede enviar un mensaje a
todos los miembros del grupo para anunciar su presencia.
En un grupo cerrado los grupos deben estar abiertos a la opción de admitir otro
miembro.
Para salir de un grupo, basta que un miembro envíe un mensaje de despedir a
todos.
Si un miembro falla, sale del grupo, pero el problema es que no se anuncia su
salida, los demás miembros descubren esto al observar que el miembro ya no
responde, una vez verificado que el miembro esta inactivo, puede eliminarse del
grupo.
Otro aspecto problemático, es que la salida y la entrada al grupo debe
sincronizarse con el envío de mensajes.
Si falla tantas máquinas, el grupo ya no puede funcionar, se necesita cierto
protocolo para reconstruir el grupo.
Direccionamiento al grupo
Darle a cada grupo una dirección.
Transmisión Multiple
Cada mensaje enviado a la dirección del grupo se puede multitransmitir, de esta
forma, el mensaje será enviado a todas las máquinas que lo necesiten y a
ninguna más.
Transmisión Simple
Cada nucleo recibirá el mensaje y extraerá de él la dirección del grupo. Si
ninguno de los procesos en la máquina es un miembro del grupo, entonces se
descarta la transmisión. En caso contrario se transfiere a todos los
miembros del grupo.
Unitransmisión
El núcleo de la máquina emisora debe contar con una lista de las máquinas que
tienen proceso perteneciente al grupo para enviar a cada uno un mensaje
puntual.
Pedir al emisor una lista explícita de todos los destinos.
Desventaja: No es transparente. Cuando combia la membresia del grupo, los
procesos del usuario deben actualizar sus listas de miembros.
Direccionamiento de Predicados
Se envía cada mensaje a todos los miembros ya descritos, pero cada mensaje
contiene un predicado( expresión booleana). Para ser evaluado. El predicado
puede utilizar el número de máquina del receptor, sus variables locales a otros
factores, si el valor del predicado es verdadero se acepta el mensaje, si
es falso el mensaje se descarta.
Primitivas Send y Receive
Para enviar un mensaje uno de los parámetros de send indica el destino, si es
una dirección de un proceso, se envía un mensaje a este proceso en particular,
si es una dirección de grupo, se envía un mensaje a todos los miembros del
grupo, un segundo parámetro de send apunta hacia el mensaje a enviar.
Receive: Indica una disposición para aceptar un mensaje y es pósible que se
bloque hasta disponer de uno. Si se combinan las formas de comunicación,
entonces receive termina su labor cuando llega un mensaje puntual a un
mensaje de grupo.
Atomicidad
La atomicidad es la propiedad del todo o nada, en la entrega de mensajes, es
decir cuando se envía un mensaje a un grupo, este deberá de llegar de manera
correcta a todos los miembros del grupo o a ninguno.
Ordenamiento de Mensajes
Los mensajes tienen que ser enviados por pedazos.
El problema es cuando dos procesos contienden por el accesso a una LAN.
La mejor garantía es la entrega inmediata de todos los mensajes en el orden en
que fueron enviados.
Se debe hacer un ordenamiento con respecto al tiempo global con cada elemento.
Otra manera de corregir es no permitir a los procesos actualizar los
recursos, mientras otro los este ocupando.
Escalabilidad
Hacer más grande el sistema
No se deben cambiar los patrones de comunicación cuando se agreguen uno o más
elementos se deben conservar las políticas de comunicación( atomicidad,
ordenamiento de mensajes, etc.)
Se deben utilizar compuertas.
Sincronización de Relojes
Propiedad de los algoritmos distribuidos
La información relevante se distribuye entre varias máquinas.
Los recursos toman las decisiones solo con base en la información disponible en
forma local.
Debe evitarse un punto de falla en el sistema.
Existe un reloj común o alguna otra fuente precisa de tiempo global.
Cronometro
Un cronometro de computadora es por lo general un cristal de cuarzo trabajando
con precisión. Cuando se mantiene sujeto a tensión, un cristal de cuarzo oscila
con frecuencia bien definida que depende del tipo de cristal la forma en que se
corte y la magnitud de tensión. A cada cristal se le asocian dos registros un
contador y un registro mantenedor.
Cada oscilación del cristal disminuye en uno al contador, cuando el contador
toma el valor cero, se genera una interruupción y el contador se vuleve a
cargar mediante el registro mantenedor de esta forma es posible programar un
cronometro de modo que genere una interrupción 60 veces por cada segundo, cada
interrupción recibe el nombre de Marca de Reloj.
Distorción del Relog
Cuando un sistema tiene n computadoras, los n cristales correspondientes
oscilaran a tasa un poco distintas, lo que provoca una perdida de sincrónica en
los relojes y que al leerlos tengan valores distintos. La diferencia entre los
valores de tiempo se llama distorsión del relog.
Relojes Lógicos
Cuando los relojes están sincronizados sin importar que esta sincronización
coincida con la hora real del sistema.
Relojes físicos
Cuando la hora de sincronzación de los relojes corresponde a la hora real del
sistema.
SEGUNDO SOLAR: 1/86400 de un día solar (24 hrs. En un día cada
hora con 3600 segundos).
SEGUNDO SOLAR PROMEDIO: Es la cantidad resultante de calcular la
longitud del día mediante la medición de un gran número de días y tomar su
promedio antes de dividirlo entre 86400.
TAI
Tiempo Atómico Internacional, es el promedio de las marcas de los relojes de cesio
133 a partir de la media noche del 1 de enero de 1958 dividido entre
9129631770.
WWV
Estacion de radio de onda corta con las siglas WWV desde Fort Collins Colorado.
Transmite un pulso corto al inicio de cada segundo UTC, la precisión es de
cerca de +/- 1 milisegundo, pero debido a la fluctuación de la
atmosferica que puede afectar la longitud de la trayectoria de la señal,
en la practica la precisión no es mejor que +/- 10 milisegundo.
UTC
TiempoCoordenado Universal, es la base de todo el sistema de mantenimiento
moderno de la hora.
TRANSITO DE SOL
Cuando el sol alcanza su punto aparentemente mas alto en el cielo.
DIA SOLAR
El intervalo entre 2 tránsitos consecutivos del sol.
![]()