


Next: About this document ...
Up: Clustering Narrow-Domain Short Texts
Previous: Conclusions
- 1
- M. Alexandrov, A. Gelbukh, and P. Rosso: An Approach to Clustering Abstracts, In Proceedings of the 10th International Conference NLDB-05, volume 3513 of Lecture Notes in Computer Science, pages 275–-285, Springer-Verlag, 2005.
- 2
- C.H. Bennett, P. Gács, M. Li, P. Vitányi, and W. Zurek: Information Distance, IEEE Trans. Inform. Theory, 44:4, pages 1407-1423, 1998.
- 3
- B. Bigi, Y. Huang, R. d. Mori: Vocabulary and Language Model Adaptation using Information Retrieval, In Proceedings of the ECIR-2003, volume 2633 of Lecture Notes in Computer Science, pages 305–-319, Springer-Verlag, 2003.
- 4
- B. Bigi: Using Kullback-Leibler Distance for Text Categorization, In Proceedings of the ECIR-2003, volume 2633 of Lecture Notes in Computer Science, pages 305–-319, Springer-Verlag, 2003.
- 5
- B. Bigi, R. d. Mori, M. El-Bèze, T. Spriet: A fuzzy decision strategy for topic identification and dynamic selection of language models, Special Issue on Fuzzy Logic in Signal Processing, Signal Processing Journal, 80(6):1085-1097, 2000.
- 6
- A. D. Booth: A Law of Occurrences for Words of Low Frequency, Information and control, 10(4):386–-393, 1967.
- 7
- P. Burman, A comparative study of ordinary cross-validation,
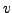 -fold cross-validation and the repeated learning-testing methods, Biometrika 76(3):503-514, 1989.
-fold cross-validation and the repeated learning-testing methods, Biometrika 76(3):503-514, 1989.
- 8
- C. Carpineto, R. d. Mori, G. Romano, B. Bigi: An information-theoretic approach to automatic query expansion, ACM Transactions on Information Systems, 19(1):1–-27, 2001.
- 9
- I. Dagan, L. Lee, F. Pereira: Similarity-based models of word cooccurrence probabilities, Machine Learning, 34(1-3):43-–69, 1999.
- 10
- B. Fuglede, F. Topsøe: Jensen-Shannon Divergence and Hilbert space embedding, IEEE Int Sym. Information Theory, 2004.
- 11
- H. Jiménez, D. Pinto, and P. Rosso: Uso del punto de transición en la selección de términos índice para agrupamiento de textos cortos, Procesamiento del Lenguaje Natural, 35(1):114–-118, 2005 (in Spanish).
- 12
- S. C. Johnson: Hierarchical Clustering Schemes, Psychometrika, 2:241-254, 1967.
- 13
- S. Kullback, R. A. Leibler: On information and sufficiency, Annals of Mathematical Statistics, 22(1):79-86, 1951.
- 14
- T. Liu, S. Liu, Z. Chen, and W. Ma: An evaluation on feature selection for text clustering, In T. Fawcett and N. Mishra, editors, ICML, pages 488–-495, AAAI Press, 2003.
- 15
- P. Makagonov, M. Alexandrov, and A. Gelbukh: Clustering Abstracts instead of Full Texts, In Proceedings of the Seventh International Conference on Text, Speech and Dialogue (TSD 2004), volume 3206 of Lecture Notes in Artificial Intelligence, pages 129–-135, Springer-Verlag, 2004.
- 16
- A. Montejo-Ráez, L. A. Ureña-López, and R. Steinberger: Categorization using bibliographic records: beyond document content, Procesamiento del Lenguaje Natural, 35(1):119–-126, 2005.
- 17
- R. d. Mori: Spoken Dialogues with Computers, Academic Press, 1998.
- 18
- V. Pekar, M. Krkoska, S. Staab. Feature Weighting for Co-occurrence-based Classification of Words, In Proceedings of the 20th Conference on Computational Linguistics, COLING-2004, 2004.
- 19
- D. Pinto, H. Jiménez-Salazar, and P. Rosso: Clustering abstracts of scientific texts using the transition point technique, In Alexander F. Gelbukh, editor, CICLing, volume 3878 of Lecture Notes in Computer Science, pages 536–-546. Springer-Verlang, 2006.
- 20
- D. Pinto, P. Rosso, A. Juan, and H. Jiménez, : A Comparative Study of Clustering Algorithms on Narrow-Domain Abstracts, Procesamiento del Lenguaje Natural, 37(1):43-49, 2006.
- 21
- D. Pinto, and P. Rosso: KnCr: A Short-Text Narrow-Domain Sub-Corpus of Medline, In Proceedings of TLH-ENC06, pages 266-269, 2006.
- 22
- M. F. Porter: An algorithm for suffix stripping, In Program, 14(3), 1980.
- 23
- K. Shin and S. Y. Han: Fast clustering algorithm for information organization, In A. F. Gelbukh, editor, CICLing, volume 2588 of Lecture Notes in Computer Science, pages 619–-622, Springer-Verlang, 2003.
- 24
- C. J. Van Rijsbergen: Information Retrieval, 2nd edition, Dept. of Computer Science, University of Glasgow, 1979.
- 25
- Y. Yang: Noise reduction in a statistical approach to text categorization, In Proceedings of SIGIR-ACM, pages 256–-263, 1995.
- 26
- Y. Yang , J. O. Pedersen. A comparative study on feature selection in text categorization. In Proc. ICML, pages 412-420, 1997.
- 27
- J. Ziv and N. Merhav: A measure of relative entropy between individual sequences with application to universal classification, IEEE Transactions on Information Theory, 39(4):1270-1279, 1993.
David Pinto
2007-05-08